
Running Large Language Models (LLMs) on the edge is a fascinating area of research, and opens up many use cases that require data privacy or lower cost profiles. With libraries like ggml coming on to the scene, it is now possible to get models anywhere from 1 billion to 13 billion parameters to run locally on a laptop with relatively low latency.
In this tutorial, we are going to walk step by step how to fine tune Llama-2 with LoRA, export it to ggml, and run it on the edge on a CPU.
We assume you know the benefits of fine-tuning, have a basic understanding of Llama-2 and LoRA, and are excited about running models at the edge 😎.
We will be following these steps:
- Run Llama-2 on CPU
- Create a prompt baseline
- Fine-tune with LoRA
- Merge the LoRA Weights
- Convert the fine-tuned model to GGML
- Quantize the model
Note: All of these library are being updated and changing daily, so this formula worked for me in October 2023
Run Llama-2 on CPU
Before we get into fine-tuning, let's start by seeing how easy it is to run Llama-2 on GPU with LangChain and it's CTransformers interface.
To get up and running quickly TheBloke has done a lot of work exporting these models to GGML format for us. You can find many variations of Llama-2 in GGML format for download here.
First install the dependencies.
pip install langchain pip install ctransformers
Then download the raw model file.
mkdir models wget -O models/llama-2-7b-chat.ggmlv3.q8_0.bin https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/resolve/main/llama-2-7b-chat.ggmlv3.q8_0.bin
Finally run the model on the CPU with the following script.
from langchain.llms import CTransformers
from langchain.callbacks.base import BaseCallbackHandler
# Handler that prints each new token as it is computed
class NewTokenHandler(BaseCallbackHandler):
def on_llm_new_token(self, token: str, **kwargs) -> None:
print(f"{token}", end="", flush=True)
# Local CTransformers wrapper for Llama-2-7B-Chat
llm = CTransformers(
model="models/llama-2-7b-chat.ggmlv3.q8_0.bin", # Location of downloaded GGML model
model_type="llama", # Model type Llama
stream=True,
callbacks=[NewTokenHandler()],
config={'max_new_tokens': 256, 'temperature': 0.01}
)
# Accept user input
while True:
prompt = input('> ')
output = llm(prompt)
print(output)The first time you run inference, it will take a second to load the model into memory, but after that you can see the tokens being printed out as they are predicted.
The Task: Dad-Joke LLM
When fine-tuning, it is import to first ask yourself "why?". What do you think the base model is incapible of doing? How are you going to test this hypothesis?
For this example, we are going to see if we Llama-2 can complete joke setups with punchlines. An example from the r/dadjokes reddit:
Setup: My friend quit his job at BMW
Punchline: He wanted Audi.Bah dun tis' 🥁
Comedy is a fun example of fine-tuning as everyone has a different sense of humor. What may be funny to me, might not be funny to you. In theory there are many ways to fine-tune an LLM to have your exact sense of humor. Language models that are simply trained to predict the next word, can be pretty dry and literal, so our hypothesis is that we can use fine tuning to spice them up.
Creating a Baseline Prompt
Let's start by poking Llama-2 with a stick to see if it is funny or not.

When evaluating LLMs, I like to have have a few specific examples in mind, and do a quick sanity check of how a base model performs.
While "a few examples" does not give you a quantitative value for how well your model is performing, it is surely what your customers will do first, so getting a sense of the initial experience is important.
In this case, we will try to get Llama-2 to be a "hilarious, dry, one-liner standup comedian"
Prompt:
You are a hilarious, dry, one-liner standup comedian. Please complete the following joke setup with a punchline: My friend quit his job at BMW.Llama-2 Response:
Why? Because he couldn't ________________.
Hint: Think of something that might be difficult or frustrating for someone working in a car factory.As you can see, the model kind of got the gist, but couldn't complete the task. Not too funny if you ask me.
N-Shot Prompt
The next logical step is to create an N-Shot prompt to prime the model with some more examples. Coming up with an N-shot prompt is quicker to iterate on than an entire fine-tuning process, so is worth a shot (pun intended).
N-shot prompting involves giving the LLM more examples of the task you want to perform. It is slightly more expensive to process all the tokens on this single run, but is faster than kicking off an entire fine-tuning run which could take a couple hours.
To come up with examples for our N-shot prompt I will grab the top 5 from a dataset on Oxen.ai. Make sure they are from the "training" data file, so that we are not contaminating our tests.
N-Shot Prompt:
You are a hilarious, dry, one-liner standup comedian. Please complete the following jokes setups with punchlines:
Someone told me the unit of power was Joules
I was like Watt?
I asked my dog "what's seven minus seven?"
He said nothing.
What do dyslexic Zombies eat?
Brians
What did the drummer name his daughters?
Anna 1, Anna 2, Anna 3, Anna 4
My friend quit his job at BMW.Llama-2 Response:
He's now working for Tesla. I asked him why and he said "the future is electric."This response is quite literal, not quite the dad joke I am looking for. I poked around a little more and felt like at this point fine-tuning is worth trying!
Fine-Tuning on the Dad-Jokes dataset
When it comes to fine-tuning, the hardest part of the process tends to be collecting a dataset large enough to have an impact on model performance. There are many ways to start collecting data, but luckily we can just use a pre-collected dataset from Oxen.ai.
You can explore the full dataset here.
LoRA + Peft
For this example, we will be fine-tuning Llama-2 7b on a GPU with 16GB of VRAM. We use the peft library from Hugging Face as well as LoRA to help us train on limited resources. This took a few hours to run on a 16GB NVIDIA GeForce RTX 3080. You can rent a GPU from a cloud resource to do this step, just make sure it has anywhere above 16GB of GPU memory.
To run the fine-tuning, point the training to a parquet file of examples and specify where you want to store the results. To download the data, you can use the oxen download command or from the Oxen Hub UI.
Next you can install oxen if you have not already.
brew tap Oxen-AI/oxen
brew install oxenThen you can run:
oxen remote download ox/Dad-Jokes data/train.parquetNote: I have found the load_dataset function works better with parquet files and sometimes gets hung up on jsonl, so the data has been concatenated together into a parquet file with a single "text" field.
oxen df train.parquet
shape: (5_041, 1)
┌───────────────────────────────────┐
│ text │
│ --- │
│ str │
╞═══════════════════════════════════╡
│ You are a hilarious, dry, one-li… │
│ You are a hilarious, dry, one-li… │
│ You are a hilarious, dry, one-li… │
│ You are a hilarious, dry, one-li… │
│ … │
│ You are a hilarious, dry, one-li… │
│ You are a hilarious, dry, one-li… │
│ You are a hilarious, dry, one-li… │
│ You are a hilarious, dry, one-li… │
└───────────────────────────────────┘Each row in the parquet dataset now looks like this:
You are a hilarious, dry, one-liner standup comedian. Please complete the following jokes setups with punchlines:
I asked my dog "what's seven minus seven?"
He said nothing.
<END>Once you have the dataset, simply point the fine tuning script to the dataset, and provide a directory to save the models in.
python fine_tune.py <train.parquet> <results_dir>Full Fine-Tuning Code
# fine_tune.py
from datasets import load_dataset
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer, TrainingArguments
from peft import (
get_peft_model,
LoraConfig,
TaskType,
prepare_model_for_int8_training,
)
from trl import SFTTrainer
from transformers import LlamaForCausalLM, LlamaTokenizer
import sys, os
if len(sys.argv) != 3:
print("Usage: python fine_tune.py <dataset.parquet> <results_dir>")
exit()
dataset_file = sys.argv[1]
output_dir = sys.argv[2]
# Load the parquet file
dataset = load_dataset("parquet", data_files={'train': dataset_file})
dataset = dataset['train']
print(dataset)
base_model_name = "meta-llama/Llama-2-7b-hf"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
device_map = {"": 0}
base_model = AutoModelForCausalLM.from_pretrained(
base_model_name,
quantization_config=bnb_config,
device_map=device_map,
trust_remote_code=True,
use_auth_token=True
)
base_model.config.use_cache = False
# More info: https://github.com/huggingface/transformers/pull/24906
base_model.config.pretraining_tp = 1
def create_peft_config(model):
from peft import (
get_peft_model,
LoraConfig,
TaskType,
prepare_model_for_int8_training,
)
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.05,
target_modules = ["q_proj", "v_proj"]
)
# prepare int-8 model for training
model = prepare_model_for_int8_training(model)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
return model, peft_config
tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
model, lora_config = create_peft_config(base_model)
training_args = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=1,
# Tutorials I saw often used gradient_accumulation_steps=16, but I kept running out of memory.
gradient_accumulation_steps=4,
warmup_steps=2,
learning_rate=2e-4,
logging_steps=1,
)
max_seq_length = 1024
trainer = SFTTrainer(
model=base_model,
train_dataset=dataset,
peft_config=lora_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_args,
)
trainer.train()
output_dir = os.path.join(output_dir, "final_checkpoint")
trainer.model.save_pretrained(output_dir)Merge the LoRA Weights
Once you have finished training, there are a couple artifacts. LoRA will output a set of adapter weights that you will have to merge with your base model weights. Let's take a look at the LoRA adapter weights.
The final_checkpoint directory which should contain two files adapter_config.json and adapter_model.bin. You will notice these files are quite small compared to the actual LLM. The adapter_model.bin file is only 17mb.
ls -trl results/final_checkpoint
-rw-rw-r-- 1 ox ox 464 Oct 18 19:19 README.md
-rw-rw-r-- 1 ox ox 17M Oct 18 19:19 adapter_model.bin
-rw-rw-r-- 1 ox ox 446 Oct 18 19:19 adapter_config.jsonThis can slightly confusing if you are not familiar with the concept of LoRA, but these are a set of smaller weights that need to be merged with the base model weights.
To merge the weights with the meta-llama/Llama-2-7b-hf model simply run the following script.
python merge_lora_model.py results/final_checkpoint/ results/merged_model/Full Merge Code
# merge_lora_model.py
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
import sys
import torch
from prompt_toolkit import prompt
if len(sys.argv) != 3:
print("Usage: python merge_lora_model.py <lora_dir> <output_dir>")
exit()
device_map = {"": 0}
lora_dir = sys.argv[1]
base_model_name = "meta-llama/Llama-2-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True)
model = AutoPeftModelForCausalLM.from_pretrained(lora_dir, device_map=device_map, torch_dtype=torch.bfloat16)
model = model.merge_and_unload()
output_dir = sys.argv[2]
model.save_pretrained(output_dir)Now you will notice you have a directory with 13GB of data. This is the full Llama-2 model with the merged adapter weights.
ls -trlh results/merged_model/
total 13G
-rw-rw-r-- 1 ox ox 183 Oct 19 12:47 generation_config.json
-rw-rw-r-- 1 ox ox 657 Oct 19 12:47 config.json
-rw-rw-r-- 1 ox ox 9.3G Oct 19 12:48 pytorch_model-00001-of-00002.bin
-rw-rw-r-- 1 ox ox 24K Oct 19 12:48 pytorch_model.bin.index.json
-rw-rw-r-- 1 ox ox 3.3G Oct 19 12:48 pytorch_model-00002-of-00002.binConvert fine-tuned to GGML
You can load this full model onto the GPU and run it like you would any other hugging face model, but we are here to take it to the next level of running this model on the CPU like we did at the start of the tutorial.
This was the shakiest part so far, out of the box Llama.cpp did not support hugging face style tokenizers, so I dove into the issues and found a pull request where someone implemented it.
 ggerganov
ggerganovFrom there I cloned the forked repository and ran the convert script from there. Maybe by the time you read this, it will have been merged into the main project.
git clone https://github.com/strutive07/llama.cpp.gitLlama.cpp has a script called convert.py that is used to convert models to the binary GGML format that can be loaded and run on CPU. Note: These parameters worked with the commit 5a1f178091bf0d0be985f91d4a7f520ef156a122 on the convert_hf_vocab branch.
python /path/to/llama.cpp/convert.py results/merged_model/ --outtype f16 --outfile results/merged.bin --vocab-dir meta-llama/Llama-2-7b-hf --vocabtype hfThis should output a 13GB binary file at results/merged.bin that is ready to run on CPU with the same code that we started with!
Please reach out to hello@oxen.ai if you get to this step and find that the code has been merged or there is a new way to do this, and I will update this part of the example.
Quantize GGML Model
Part of the appeal of the GGML library is being able to quantize this 13GB model into smaller models that can be run even faster. There is a tool called quantize in the Llama.cpp repo that can be used to convert the model to different quantization levels.
First you need to build the tools in the Llama.cpp repository.
cd /path/to/llama.cpp
mkdir build
cd build
cmake --build . --config ReleaseThis will create the tools in the bin directory. You can now use the quantize tool to shrink our model to q8_0 by running:
/path/to/llama.cpp/build/bin/quantize results/merged.bin results/merged_ggml_q8_0.bin q8_0Voila! Now we have a 6.7 GB model at results/merged_ggml_q8_0.bin
Evaluation
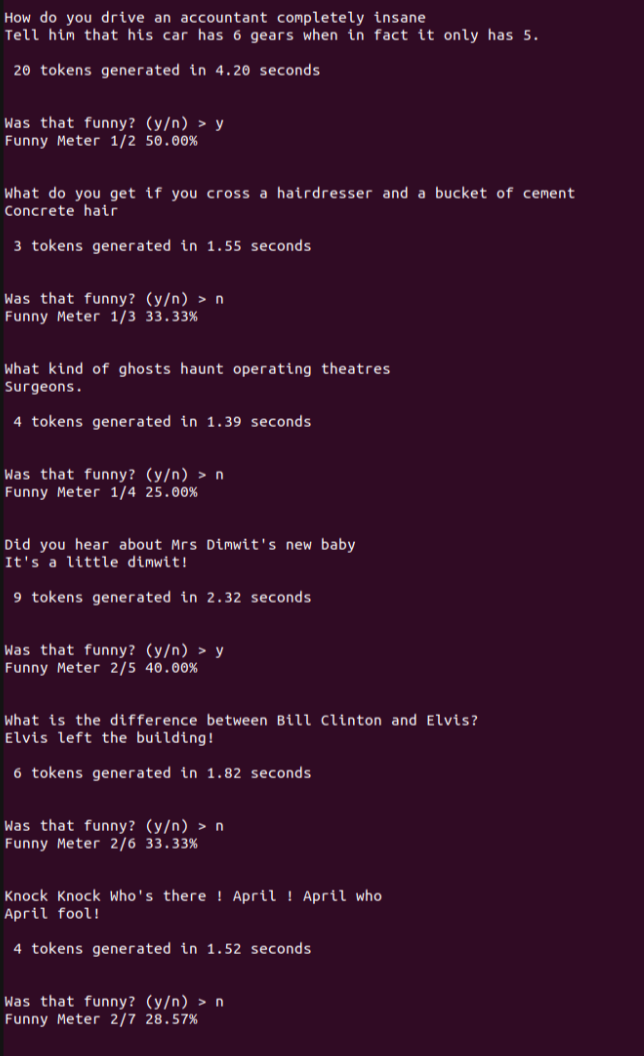
Next we want to get a better sense of how funny our quantized, fine-tuned model actually is.
Instead of simply running it on one example, I wrote a script to generate setups and punchlines from this model, let you mark them as funny-or-not. This way we can have a running "Funny-O-Meter" score of how funny you think the LLM is.
The script also saves out a line delimited json file we can later use to fine tune further, or simply track progress.
You can find the evaluate script here.
python run_on_cpu.py --prompt prompts/base_prompt.txt
Next Steps
There are a few fun places you could explore next. One is to evaluate different quantization sizes of the models and compare your accuracy vs speed. Quantization inherently creates information loss, so the smaller the model after quantization, the less accurate it is likely to be.
Another would be to collect data that you actually think is funny, and train the model on this data. If you create any creative datasets feel free to upload them to Oxen.ai. We would love to see what you build 😎.