
All machine learning solutions start with a good dataset. The author of “Deep Learning with Python” goes as far as stating
Spending more effort and money on data collection almost always yields a much greater return on investment than spending the same on developing a better model. — François Chollet
Yet we are still in the early days of dataset management. Many times a machine learning project or tutorial starts with
First, let's download the 786M ZIP archive of the raw data:
!curl -O https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip
Imagine if we still wrote code by dropping zip files on a shared server to each other. It would be a mess. It would take forever to debug and get a new release out. Luckily for us people invented version control systems to solve this exact problem.
Data is not a static asset, and should not be treated like one. As your dataset evolves it quickly becomes apparent why you want a rich history of all the changes. Knowing who added what, when, and having commits to revert back to saves us in the software world all the time. Yet it is still common practice to dump data in cloud storage and train our models off of static data artifacts.
At Oxen.ai we are building data point level version control, optimized for machine learning datasets. Our goal is to help you collaborate on your data, extend it, and make your machine learning system smarter through adding data instead of writing new lines of code. Data point level version control helps you get back the the exact state of the data when you reached that accuracy number you were targeting.
Machine learning datasets are a unique version control problem because they are much larger than code bases. Often they have many data files, of varying sizes, as well as other large data files in the form of csv, parquet or json files. Traditionally it has been easiest to compress and zip up this kind of data, maybe with a timestamp and a clever name, and get back to it later. This is not scalable and can come back to bite you later.
To illustrate the power of Oxen, let’s get started with an example problem and dataset.
When life gives you lemons, make sure they are the right version
Imagine you want to start a lemonade stand. Not just any old lemonade stand. You are building a futuristic lemonade factory with advanced computer vision to squeeze the highest quality lemons out of the batch. By scanning and sorting every lemon on the line with computer vision, you plan to brew the perfect lemonade every time.
You want your lemonade factory line to be able to automatically filter out lemons that look like the top row, and keep the juicy ripe ones on the bottom row.

Since this is a lemonade factory from the future, you want production grade processes for your data. Good data in, good lemonade out.
To get started let’s grab our initial data lemon dataset from Kaggle in the form of a zip file (which you can download here). This is a fine first step, but you quickly realize the photos are all taken on the same background, and there aren’t that many of them.

Over time we will want to add more photos and be able to extract more granular information about the lemons as they roll through our factory.
Simply downloading the zip file and adding to it may not seem like a problem at first. Pressing ctrl-z in your code editor may not have seemed like a problem when you first started programming. But if you want to be a proper software engineer, you use source code management. If you want to be a proper data scientist or machine learning engineer, you should be using a data versioning system.
Data Version Control Made Easy With Oxen
Enter Oxen 🐂 to save the day.
Oxen is command line tooling that mirrors git, so that there is minimal learning curve to get up and running with an Oxen repository.
First make sure you have the oxen client installed, you can find installation instruction here.
Once you have the data downloaded, unzip it into a the working directory.
unzip archive.zip
rm archive.zip
cd lemons_dataset
First initialize the repo with the init command.
oxen init
You can use the status command to view a summary of the files that are not yet staged.
oxen status
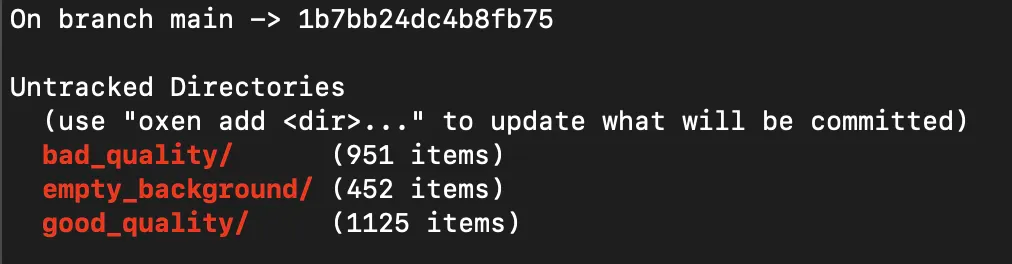
Since ML datasets typically have many files, Oxen rolls up and summarizes the directories so you can quickly get a sense of the scale of the data.
For example if you stage the good_quality images directory with over 1,000 and run status again, you will see a nice summary in the status.
oxen add good_quality/
oxen status
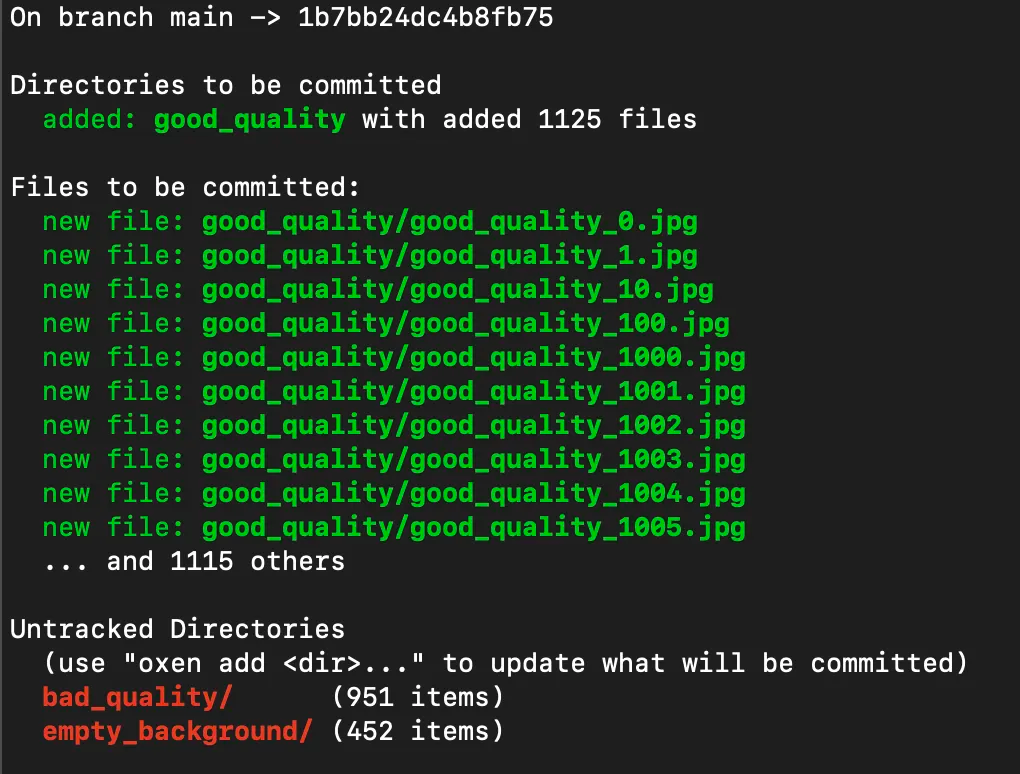
To commit the changes to the history, you can run the commit command with the -m flag for a message. This command will version and backup the files into the hidden .oxen/ directory so that you can always revert to them later.
oxen commit -m "adding good quality lemons"
Next let’s add and commit the rest of the images.
oxen add .
oxen commit -m "adding bad quality lemons, and background images"
To see the commit history simply use the log command.
oxen log

Now say we want to collect 1000 more images of lemons, with different lighting, different backgrounds, and a variety of qualities. Simply copy the images into the directory, add and commit them.
To roll back to the dataset at any point in time you can simply run the checkout command.
oxen checkout COMMIT_ID
Congratulations 🎉 you have just taken the first steps in making your machine learning data pipeline more auditable and robust.
At this point, what we have is a history of changes and the ability to revert changes. If you are familiar with using git for code, you can start to extrapolate how similar tooling optimized data would be powerful. You can integrate commit ids into training pipelines, tie them to model versions, run experiments on branches, etc.
To see the variety of features and dive more into how Oxen can help make your ML workflow more robust, please check out the developer documentation.
If you found this post interesting please tag us on Twitter at @oxendrove or reach out at hello@oxen.ai.
We have also built out a web interface called “Oxen Hub” and would love early feedback, for access you can sign up here.
Thanks & Moo’
~ 🐂 team
At OxenAI we want to see what you are building! Reach out at hello@oxen.ai, follow us on Twitter @oxendrove, dive deeper into the documentation, or Sign up for Oxen today. http://oxen.ai/register.